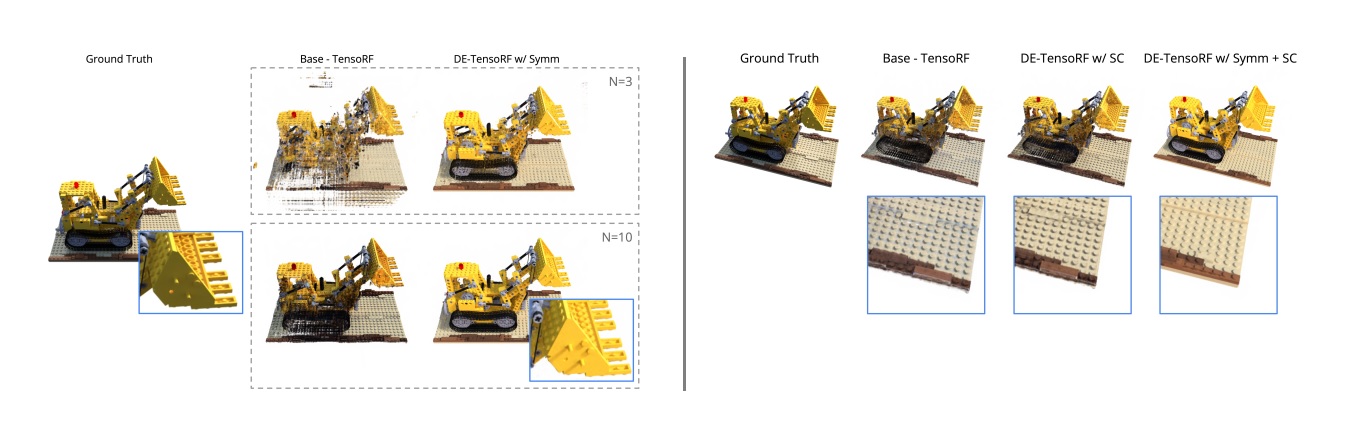
Developed DE-TensoRF, a model that can render high-quality 3D objects with as few as 3 input images, and in under 15 min on a single GPU. Proposed three techniques to achieve data-effiency: (i) Obtain unseen views using symmetry (ii) Semantic conditioning (iii) Semantic Loss.
Abstract: Neural radiance fields (NeRFs) are models that can synthesize novel views of complex 3D scenes from a set of 2D images associated with their camera positions. However, NeRFs suffer from two drawbacks: they require a large amount of training data in the form of images from multiple camera locations, and they take a long time to train. To overcome the second challenge, TensoRF uses tensor decomposition and factorization to speed up rendering. We propose to extend TensorRF to make it data efficient (DETensoRF). We explore two techniques to improve TensoRF’s robustness to data scarcity and occlusion. First, we use priors about the geometric structure and symmetry of the scene to obtain unseen views with new camera positions using existing seen views. Second, we use a pre-trained CLIP ViT model to ensure semantic similarity between all views as a conditioning method, as well as an additional loss term. We conduct experiments on objects from the Synthetic-NeRF dataset, which contain images of objects with complex geometry. Unlike TensoRF, DE-TensoRF is able to produce higher quality 3D reconstructions with a limited set of seen views.
Results


| GitHub | Report |